1) 아나콘다 다운로드
주피터 노트북, BeautifulSoup 등을 비롯한 다양한 파이썬 패키지를 미리 포함하고 있는 아나콘다는 실습 뿐 아니라 실 개발 환경으로도 사용될 수 있는 편리한 파이썬 배포판이다. 특히, 주피터 노트북은 프로그램을 통해 분석한 결과를 가시적으로 모니터링할 수 있다는 큰 장점으로 인해 데이터 사이언스 진영에서 Apache Zeppelin과 함께 큰 인기를 끌고 있다.
따라서 우리는 주피터 노트북을 사용하기 위해 먼저 아나콘다를 다운로드 하기로 한다. 먼저 ‘링크’ 에 접속하여 본인의 운영체제에 맞는 설치 파일을 받아준다. 이후, 설치 과정에서는 특별한 설정을 하지 않고 default 값으로 설치를 완료해준다.

설치가 마무리되면, anaconda prompt를 실행시켜준다.
아래와 같이 명령어 프롬프트가 나타나면 아래의 명령어를 실행시킨다.
1
jupyter notebook
잠깐의 로딩 과정을 거친 후, 다음과 같은 화면을 지닌 브라우져가 실행될 것이다.
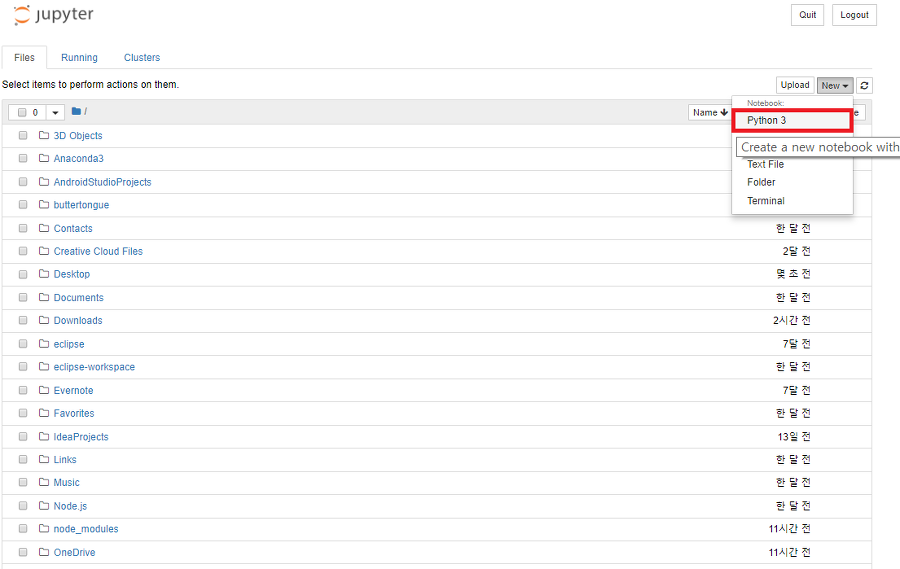
해당 화면에서 다음과 같이 ‘Python3’의 새 프로젝트를 생성해준다.
2) 크롤러 작성
새로운 프로젝트가 생성되면 가장 위에는 아래와 같은 코드를 작성해준다. BeautifulSoup는 웹 크롤링을 위한 파이썬의 오픈 소스 라이브러리이며, urlopen은 문자 그대로 우리가 지정한 url을 파이썬을 통해 열기 위해 import 해야 하는 모듈이다.
1
2
from bs4 import BeautifulSoup
from urllib.request import urlopen
cf. Jupyter Notebook에서는 ctrl + enter 로 해당 라인을 실행시킬 수 있으며, 편집 모드와 명령 모드는 esc키를 통해 전환이 가능하다. 또한 명령 모드에서 b 키를 통해 새로운 라인을 이전 라인의 아래에 생성할 수 있다. a 키를 통해서는 이전 라인의 위에 새로운 라인을 생성할 수 있다.
다음으로, 크롤링을 하고자 하는 사이트의 url을 지정해준다. 우리는 네이버 영화의 평점을 읽어올 것이기 때문에 네이버 무비의 url을 사용한다.
1
url = "http://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date=20180802"
이제 해당 url을 읽어와 그 결과를 page에 담고, BeautifulSoup을 통해 page를 html tag로 parsing하여 담는다.
1
2
3
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
soup
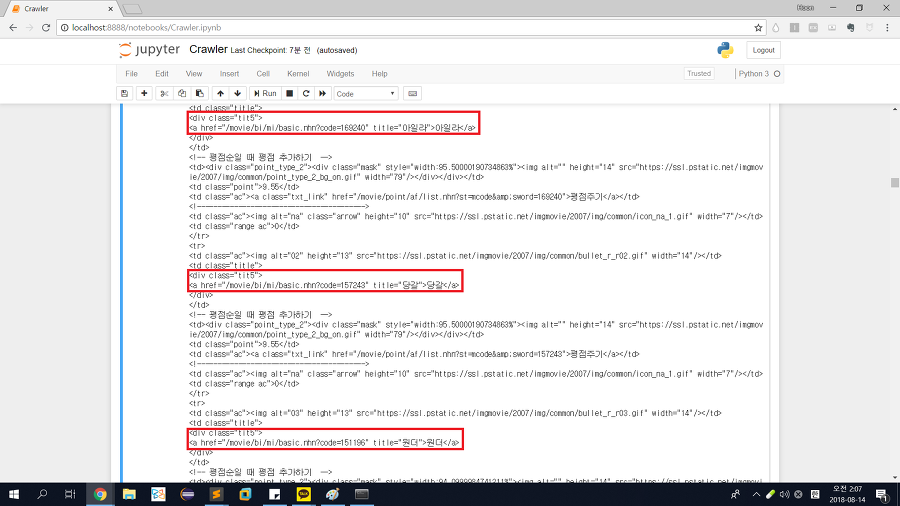
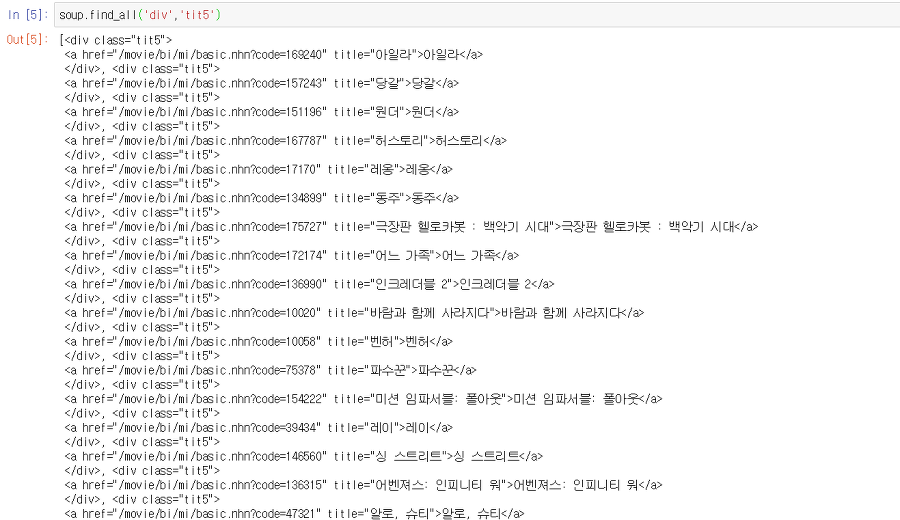
이후, html을 parsing한 soup의 html 코드를 읽어보면 우리가 찾고자 하는 영화의 제목은 div tag 중 tit5라는 class에 속한 값임을 알 수 있다. 따라서 다음과 같은 코드를 통해 모든 영화의 목록을 읽어온다.
1
soup.find_all('div','tit5')
이어서 평점의 경우, td tag의 point라는 class에 속함을 알 수 있다.

따라서 다음 코드로 해당 날짜에 존재하는 모든 영화의 제목과 평점을 읽어온다.
1
2
3
4
5
6
7
title_n = soup.find_all('div', 'tit5')
# 전체 영화의 제목 뽑아옴
movie_name = [soup.find_all('div', 'tit5')[n].a.string for n in range(0, len(title_n))]
# 전체 순위의 평점 뽑아옴
movie_point = [soup.find_all('td', 'point')[n].string for n in range(0, len(title_n))]
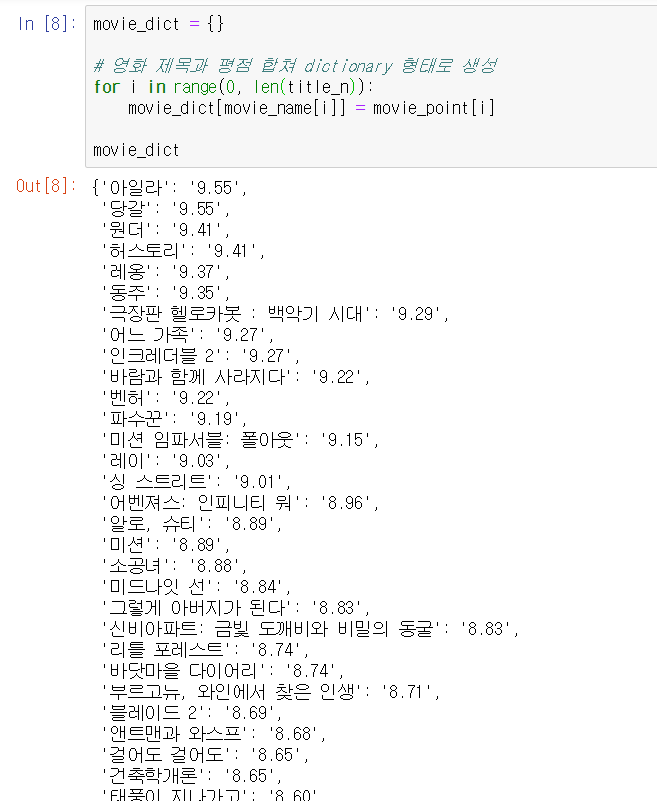
마지막으로, index를 활용하여 각 영화의 제목과 평점을 key와 value 값으로 보기 좋게 나열해볼 수 있다.
1
2
3
4
5
6
movie_dict = {}
for i in range(0, len(title_n)):
movie_dict[movie_name[i]] = movie_point[i]
movie_dict
실습한 바와 같이, 파이썬을 이용하여 웹 크롤러를 작성하는 것은 편리한 라이브러리 덕분에 기본적인 파이썬 문법과 html 및 css 태그에 대한 이해만 있다면 큰 어려움 없이 작성이 가능하다.