한국 시간으로 1월 18일 Facebook의 PyTorch 팀이 관리하는 자연어 처리 오픈소스 fairseq를 둘러보던 중 레이어 구현에 있어 작은 논리 오류를 발견하였다. 그리고 침착하게 issues 란으로 이동해 내가 발견한 오류가 이미 보고되었는지를 확인했다. 마침 본 오류는 기존에 issue로 보고되지 않은 오류였기에 내 뇌가 오류를 내고 있는지, 아니면 정말 fairseq 팀이 오류를 낸 것인지 스스로 많은 검증 절차를 거쳤다.
나름의 타이트한 검증 절차를 거친 후, 해당 오류를 실제 논리 오류로 판명낸 나는 처음으로 자연어 처리 오픈소스에 Pull Request를 날리게 되었다. 그리고 6일 뒤인 1월 24일 내가 날린 (3줄 추가 1줄 삭제에 빛나는..) Pull Request가 fairseq에 최종적으로 머지되었다! 이는 나에게 나름 의미있는 기억이기에 글로서 해당 사건을 기록해두고자 한다.
발단: 나는 왜 fairseq에 Pull Request를 날렸는가?
요즈음의 나는 자연어 처리 논문에서 제시된 모델들을 코드로 구현하는데 푹 빠져 있었다. 특히 Transfer Learning을 기점으로 일어난 자연어 처리 분야의 비약적 성능 발전으로 말미암아 거의 모든 모델들이 언어 모델을 사전 학습을 통해 거치고 나오고 있기 때문에 다양한 언어 모델 기법을 구현하는 방법들에 특히나 많은 관심을 가지고 있었다.
이러한 관심으로 인해 처음에는 모두에게 친숙한 BERT를 구현하고자 했었고, 다음으로 관심을 가진 모델은 Adaptive Input Representations for Neural Language Modeling 논문에서 제시한 Adaptive Input 레이어가 가미된 트랜스포머 모델이었다. 해당 레이어는 Hierarchical Softmax의 한계, 그리고 그 한계를 극복하기 위해 등장한 Adaptive Softmax의 성공을 출력층 뿐만 아니라 입력층에도 적용해 성능 개선을 꾀할 수 있다는 가능성을 결과로 보여준 레이어이다.
재미있는 것은 Adaptive Input 레이어가 자연어 처리 학계에서 꽤나 많은 관심을 불러 일으킨 레이어임에도 불구하고 PyTorch 프레임워크에는 공식으로 등록되지 않은 레이어라는 점이다. fast.ai라는 프레임워크로 유명한 Jeremy Howard가 직접 issue를 남겨 해당 레이어의 추가를 문의하기도 했는데, PyTorch에는 공식적으로 추가되지 않고 PyTorch의 하위 프로젝트인 fairseq에 실험용 코드로 기록되어 있다. FAIR에서 시퀀스 계열 모델을 새로이 연구할 때 마다 fairseq를 활용하기 때문에 이와 관련된 실험 코드는 모두 해당 라이브러리에 기록하고 있는 것 같았다.
그래서 이제 Adaptive Input 레이어가 PyTorch에는 없고, 내가 구현에 참조할 수 있는 코드는 모두 fairseq에 있다는 것을 알게 되었다. Facebook의 fairseq 역시 Google의 tensor2tensor 만큼 지속적으로 잘 관리되고 있는 라이브러리였기 때문에, 이번 모델 구현에 있어 fairseq의 코드를 한 번 분석해보는 것이 장기적으로 내게 큰 도움이 될 것이라는 판단이 들었고, 본격적으로 코드를 분석하기 시작했다.

근데 이게 시작부터 쉽지가 않았다. 여러 라이브러리를 활용해보신 분들은 아시겠지만 같은 레이어라도 Google 스타일이 있고, FAIR 스타일이 있고 Open AI 스타일이 있다. 이러한 스타일은 대개 정규화 기법의 적용 시점, 디코딩 기법, 바이어스의 사용 유무 등으로 인해 갈리는데 FAIR의 fairseq 팀 역시 자신들이 선호하는 스타일이 있었다. 때문에 각 레이어들이 어떠한 특성을 지니는지 까보는 일은 정말 고됐다..(근데 읽어보니 역시 이해하는데 도움은 된 것 같다) 그렇게 여러 코드를 분석하던 중 내가 구현하고자 하는 Adaptive Input 레이어를 분석하던 시기에 특이점을 하나 발견했다!
전개: 그래서 무슨 기여를 했는데?
Adaptive Input 레이어는 앞서 설명한 것처럼 Adaptive Softmax의 성공을 입력층에도 적용하고자 하는 시도이다. 이 둘의 공통적인 특징은 쉽게 이야기하면 자주 사용되는 단어 혹은 자주 예측되는 단어들의 임베딩 차원을 더 키워줘서 표현력을 풍부하게 하고, 그렇지 않은 단어들은 임베딩 차원을 작게해 표현력을 낮춰 말뭉치(혹은 예측)의 통계적 행태를 따르고자 했다는 것이다.
즉, 언어학에서 자주 사용되는 말뭉치 내 각 단어가 사용된 횟수를 계산해보면 두 번째로 많이 사용된 단어는 첫 번째로 많이 사용된 단어의 1/2, 세번 째로 많이 사용된 단어는 첫 번째로 많이 사용된 단어의 1/3 정도 사용이 된다는 Zipf’s Law의 교훈을 각 레이어에 투영하고자 한 시도라고 할 수 있다.
Adaptive Input 레이어의 관점에서 보면 해당 기법의 적용은 자주 사용된 단어의 표현력을 더 풍부하게 늘려줘 모델이 해당 단어들을 더 다양한 차원 값을 통해 학습할 수 있다는 장점이 있다. 그리고 이 뿐만 아니라 기존에 사용하던 임베딩 레이어에 Factorization을 적용하기 때문에 전체 파라미터 수가 감소한다는 사이드 이펙트 또한 취할 수 있다.
만약 기존의 사전 크기가 40,000 이었고 임베딩 차원이 400 이었다면 임베딩 레이어의 파라미터 갯수는 16,000,000 개 일 것이다. 이를 20000 개의 단어는 400 차원, 다른 20000 개의 단어는 200 차원을 취하도록 변경해보자. 결과는 다음과 같다. (20000 x 400) + (20000 x 200) + (200 x 400) = (8,000,000) + (4,000,000) + (8,000) = 12,008,000 개가 되었다. 약 4백만개의 파라미터 수가 감소되었다. 이때 마지막 (200 x 400)의 행렬은 Factorization을 취했던 작은 차원의 단어들을 모델의 입력 값의 차원으로 다시 되돌리기 위해 차원을 맞춰주는 선형변환이다.
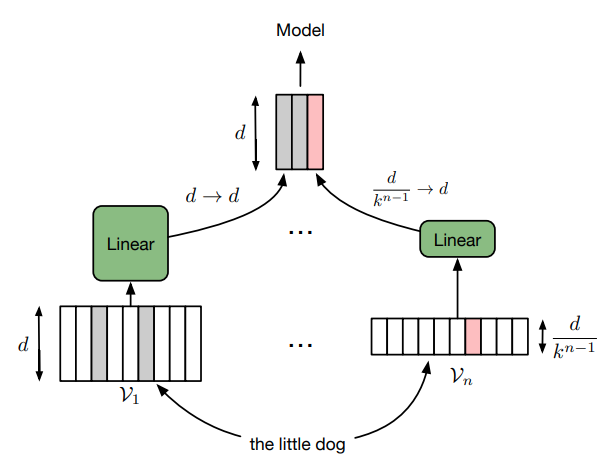
자, 이제 우리가 무슨 레이어를 이야기하고 있는지에 대해 대부분 이해가 되었을 것이다. 개념이 어렵지 않은만큼 해당 레이어의 구현 역시 크게 어렵지 않았다. 카운트 기반으로 단어 사전을 구축한 후에, 입력 값으로 들어오는 단어가 상위 단어장에 해당되면 큰 사이즈의 임베딩 레이어를 거치게 하고, 하위 단어장에 해당되면 작은 사이즈의 임베딩 레이어를 거치도록 입력층을 설계해주면 된다.
1
2
3
4
5
6
7
8
9
10
self.embeddings = nn.ModuleList()
for i in range(len(self.cutoff)):
prev = self.cutoff[i - 1] if i > 0 else 0
size = self.cutoff[i] - prev
dim = int(initial_dim // (factor ** i))
seq = nn.Sequential(
nn.Embedding(size, dim, padding_idx),
nn.Linear(dim, output_dim, bias=False)
)
self.embeddings.append(seq)
fairseq의 Adaptive Input 레이어가 해당 로직에 따라 잘 구현되어 있다. (해당 기법을 FAIR에서 제안했는데 이 로직이 당연히 맞겠지..) 그런데 가만보면 이상한 구석이 하나가 있다. 사전에는 [PAD] 토큰이 단 하나만 존재한다. 그런데 로직을 보면 여러 임베딩 레이어에 걸쳐 모두 padding_idx 옵션을 부여함으로써 모든 임베딩 레이어의 0번째 인덱스 단어가 학습되지 않도록 로직이 적용되고 있다.
[PAD] 토큰은 대개 가장 큰 표현력을 학습하는 Head 임베딩 레이어에만 포함이 된다. 이를 제외한 레이어들에서는 0번째 인덱스에 해당하는 토큰은 [PAD] 토큰이 아닌 일반 단어이므로 학습을 해주어야 한다. 따라서 Head 임베딩 레이어를 제외한 다른 임베딩 레이어에는 padding_idx 옵션을 부여하면 일부 단어가 학습되지 않는 논리적 오류가 발생하게 된다.
즉, Head를 제외한 임베딩 레이어의 0번째 토큰이 전혀 학습을 할 수 없는 Zero tensor를 부여 받게 되는 것이다. 여기서 내가 혹시나 놓친 부분이 있을까 하여 fairseq의 [PAD] 토큰 처리 방법, Head 임베딩 레이어를 제외한 임베딩 레이어들에서 0 번째 토큰이 어떻게 찍히는지 등 여러 경우의 수를 고려해보니 이 부분은 논리적 오류가 맞다는 판단이 들었다.
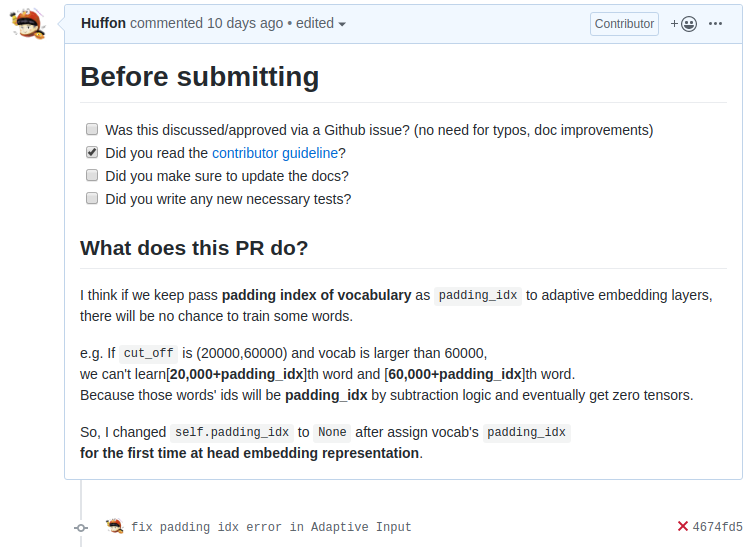
그렇게 오류를 파악한 후, 내가 파악한 오류를 검증받는 차원의 issue를 먼저 남길까 하였지만, 많은 경우의 수를 생각한 만큼 바로 수정을 가해 Pull Request를 날려도 좋겠다는 판단이 들었고 해당 오류를 정리한 Pull Request를 위 사진과 같이 남겼다. 사실 6일 동안 리뷰를 하지 않길래, “아 내가 모르는 다른 로직이 숨어 있었나보다”라는 생각을 하기도 했다. 그리고 다음부터는 무턱대고 PR을 보내지 말고, issue를 먼저 남겨야 겠다는 개인적인 교훈을 얻기도 했다. 그리고 6일 후, fairseq의 메인 컨트리뷰터인 myleott이 간단한 리뷰를 거친 후 내가 고친 PR을 머지하며 내 자연어 처리 오픈소스 첫 번째 PR을 마무리해주었다 :)
결론: 오픈 소스의 가치
소프트웨어 업계에서 오픈 소스는 많은 의미를 함축한다. 오픈 소스의 철학을 모두 이해하지는 못하지만 주니어로서 느끼는 오픈 소스는 학계의 arxiv와 더불어 우리 모두가 Openness를 추구하며, 상생의 발전을 이어가야 한다는 의미가 담긴 움직임이 아닐까라고 생각한다.
우리는 때로 오픈 소스 라이브러리로부터 많은 도움을 받지만, 작은 버그라도 발견하게 되면 이를 해당 라이브러리의 한계로 쉽게 치부해버리곤 한다. 그러나 오픈 소스 컨트리뷰터는 모든 버그를 컨트롤 해야 할 의무도 없을 뿐더러, 우리가 오픈 소스를 통해 도움을 얻었다면 본인이 발견한 버그를 제보하고 고침으로써 선순환의 고리를 만들어나가는 것이 오픈 소스를 사용하는 개발자들의 덕목이라 생각한다.

최근 Transformers 라이브러리로 유명한 Hugging Face의 Thomas Wolf가 트위터에 남긴 쓰레드가 많은 연구자들의 공감을 산 사건이 있다. Thomas Wolf는 왜 그토록 많은 연구자들이 논문만 출판하면 될 것을, 굳이 실험 코드를 잘 정제하고 다른 연구자들이 보기 쉽게 리팩토링을 거친 후 공유를 하는 것일까에 대해 이야기 했다. 많은 이유가 있겠지만 그 중 가장 보편적이고 타당한 이유는 아이디어의 공유 뿐만 아니라 코드의 공유를 통해 더 나은 실험의 발전에 기여를 할 수 있다 것이었다. 정말 멋진 일이라 생각했다. 그리고 이러한 상생의 가치를 실천하는 연구자들이 점점 더 늘어나고 있다는 사실에 감사하기도 했다.
그리고 이에 더해 기계학습 모델의 오류는 눈에 보이지 않을 때가 많다. 내가 수정한 코드 역시 미세한 오류이지만, 그렇기에 결과에 어느 정도로 영향을 미칠지도 모르지만(두 단어, 많게는 세 단어를 더 학습시키는 것이기 때문에) 이러한 명시적이지 않은 오류들을 함께 고민하고 발전시켜나가는 것 역시 분야의 발전에 있어 미약한 힘이 되는 것이라 생각한다.
최근에도 자연어 처리 관련 조그만 튜토리얼 코드를 작성하며, Hugging Face가 개발한 Tokenizers 라이브러리의 [UNK] 토큰의 처리 로직에 대한 의문이 많이 일었다. 바인딩 된 코드를 살펴보기도 했지만, 베이스를 작성한 Rust를 읽지 못하다 보니(…) 실질적인 오류를 발견하지는 못했다.
개인적으로는 이 시점이 중요한 기로가 된다고 생각한다. 1) 단순히 Tokenizers 라이브러리의 미완성도를 탓하며 다른 기존 토크나이징 라이브러리들로 회귀하던지, 2) issue를 제보해 메인 컨트리뷰터들에게 해당 의구심(혹은 에러)을 이야기하던지, 3) 혹은 더 나아가 Rust 언어를 학습해 자기가 장기적으로 사용할 것 같은 라이브러리에 직접적으로 함께 기여를 하던지. 물론 후자로 갈수록 개인적 발전에 도움이 될 뿐만 아니라, 오픈 소스 생태계에도 큰 기여를 하는 것이라 생각한다.
그동안 번역으로 여러 작은 PR을 날려본 경험이 있긴 하지만 코드 수정을 통한 PR을 처음으로 겪어보며, 개발자로서, 장래의 연구자로서, 오픈 소스의 가치를 존경하는 한 명의 사람으로서 많은 생각을 할 수 있는 소중한 시간을 가질 수 있었다. 앞으로 많은 사람들이 오픈 소스의 가치와 움직임에 공감하고 생태계를 더 풍요롭게 조성하는데 기여하면 좋겠다는 생각을 밝히며 이 글을 마친다!
P.S fairseq 팀에서는 issue로 등록되지 않은 PR의 경우, 높은 가능성으로 머지되지 않을 것이라는 문구를 작성해놓기도 했다. PR 리뷰는 issue 리뷰에 비해 리소스가 더 많이 드는 작업이기 때문에 앞으로 버그 혹은 개선점을 발견하면 issue를 먼저 남긴 후, PR을 남겨야 겠다는 개인적인 강한 교훈을 얻었다 !