들어가며…

최근 다이어트를 하고 있다. 컴퓨터 공부를 시작한 무렵부터 살이 급속도로 찌고 있었는데, 그동안 너무 안일하게 스스로를 방치한 것 같다. 이제와서야 스스로를 자책하며 간헐적 단식을 지키고 있는데 나만 다이어트를 하는 것은 조금 억울하다. 사람들이 말하길 BERT 가족들이 그렇게 다이어트를 할 필요가 있다던데 위 그림을 보니 이분들도 체중 감량을 할 필요가 있어 보이긴 한다. ML계의 양치승 관장이 되어 BERT를 다이어트 시켜보자.
이 글을 읽고 있는 독자라면 2018년 BERT의 등장 이후 자연어 처리 분야에서 새로이 나오는 모델의 사이즈가 점점 더 커지고 있다는 사실은 알고 있을 것이다. 그리고 이처럼 큰 크기의 모델의 파라미터 수를 줄이는 방법에는 Quantization, Knowledge Distlillation, Pruning 등이 있다. 이번 포스트에서는 PyTorch 공식 튜토리얼 중 Pruning Tutoiral을 참고해 Hugging face의 transformers 라이브러리 내 BERT 모델을 다이어트 시키는 방법에 대해 다루어보고자 한다.
Pruning 이란?
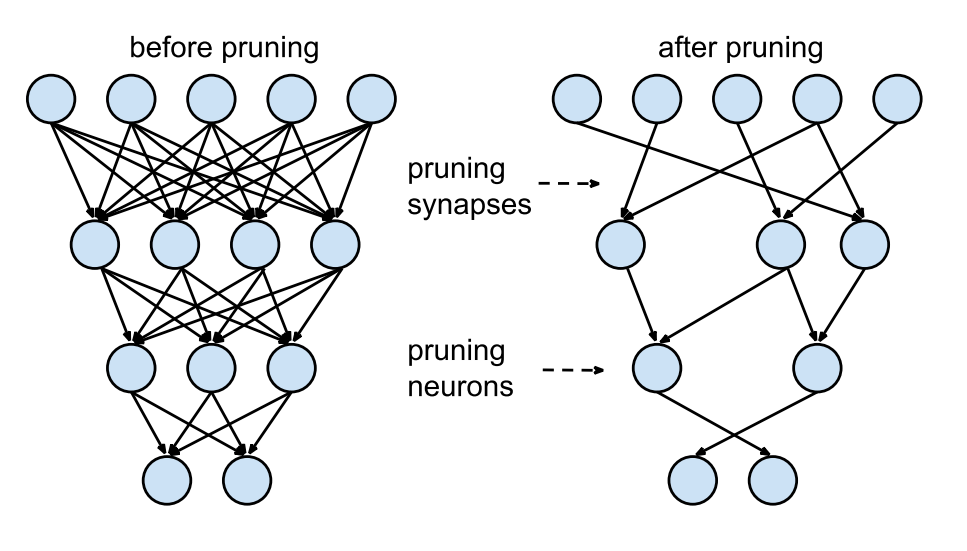
Pruning은 쉽게 이야기하자면 나무가 잘 자라게 하기 위해 가지를 쳐내는 가지치기와 같다. 네트워크를 구성하는 레이어들에는 많은 수의 뉴런이 존재하지만 모든 뉴런 간 연결을 이어주는 것은 비효율적일 수 있다. 특정 태스크를 수행하면서 큰 역할을 하지 않는 뉴런 간의 연산은 쓸데없이 연산량을 증가시키게 되기 때문이다. 따라서 위 그림처럼 특정 뉴런 간 연결을 끊어주는 것이 모델의 훈련과 경량화에 있어 효과적일 수 있으며, 우리는 이처럼 연결을 끊어주는 행위를 Pruning이라 한다.
이같이 Pruning 작업을 거친 Sparse한 모델은 이후 압축하기도 용이할뿐더러, 연결이 끊긴 뉴런 간에는 연산을 더는 진행하지 않기 때문에 훈련 및 추론 속도에도 긍정적인 영향을 미치게 된다. Pruning 작업은 해당 뉴런이 모델의 성능에 얼마나 유의미한 기여를 하느냐에 따라 진행된다. 일례로 가중치 값의 L1 혹은 L2 노름을 기준으로 뉴런의 중요도를 비교해볼 수 있는 것이다. 그리고 해당 값(L1/L2 노름, …)이 낮은 뉴런의 가중치를 0으로 Pruning 한다면 더 작고, 더 빠른 네트워크를 지닐 수 있게 된다.
대개 Pruning 이후에는 모델의 성능이 떨어지게 되는데, 이러한 성능 감소는 가중치의 중요성을 비교한 기준 (L1/L2 노름, …)이 얼마나 잘 선정되었는지에 따라 그 정도가 다르게 된다. Pruning을 활용하는 일반적인 훈련 전략은 훈련-Pruning-훈련-Pruning과 같이 Pruning과 훈련을 반복적으로 진행해 성능 감소를 만회하는 방식이다. 이처럼 반복적으로 Pruning을 진행하는 이유는 한 번에 너무 많은 뉴런의 가중치 값을 제거할 경우 모델의 성능에 치명적인 손상이 가기 때문이다. 따라서 Pruning과 훈련을 반복적으로 진행해 점진적으로 파라미터 수를 줄여나가는 것이 바람직하다.
BERT 다이어트 시키기
우리는 바퀴의 동작 원리를 이해할 필요는 있지만 재발명할 필요는 없다. Pruning 역시 이미 구현된 바퀴를 활용하면 쉽게 모델에 적용해볼 수 있다. 그리고 PyTorch에는 nn.utils.prune 이라는 이미 잘 짜여진 모듈이 있다. 해당 모듈은 사용자가 자신의 모델에 여러 가지치기 기법을 적용해볼 수 있도록 도와주는 편리한 모듈이다.
이번 시간에는 해당 모듈을 활용해 이제는 너무나도 친숙해진 허깅페이스의 transformers 라이브러리에서 잠자고 있는 BERT를 깨워 다이어트를 시켜볼 것이다. 다이어트 대상은 우리나라의 고버트(KoBERT) 씨이다. 먼저 운동에 필요한 기구들을 가져오도록 하자.
1
2
3
4
5
import torch
import torch.nn.utils.prune as prune
from transformers import BertModel
model = BertModel.from_pretrained('monologg/kobert')
다이어트에 앞서 고버트씨의 현재 무게는 얼마나 나가고 있는지 확인을 해보도록 하자.
1
2
3
sum(p.numel() for p in model.parameters() if p.requires_grad)
> 92186880
92186880 그램… 92186 킬로그램… 92톤… 고버트씨는 현재 92톤이다. 예상은 했지만 생각보다 훨씬 더 심각한 상황이다. 그리고 이 중 안면의 Self-Attention 쪽에 오른 살이 가장 심각해 보인다. 해당 부분을 먼저 집중적으로 공략하도록 하자.
1
2
3
4
5
6
7
8
9
model.encoder.layer[0].attention.self
print(module)
> BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
BERT 인코더 내 여러 모듈들 중 Self-Attention 모듈을 선택한 모습
Self-Attention Pruning: 안면 근육 다이어트
첫 번째 운동: Random Unstructured
고버트 씨의 안면 부위인 Self-Attention은 query, key, value로 이루어져 있다. 먼저 각종 운동 기법이 어떤 효과를 가져올 수 있는지를 확인하기 위해 key 부위에 실험을 진행해보기로 했다. 처음으로 진행해 볼 실험 운동은 key 내 임의의 부위에 다이어트 효과를 가져다줄 수 있는 random_unstructured이다. 해당 운동은 입력값(amount)의 퍼센티지만큼 key 부위의 살을 임의로 빼주는 기법이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
module = model.encoder.layer[0].attention.self.key
prune.random_unstructured(module, name="weight", amount=0.3)
print(list(module.named_parameters()))
> [('weight_orig', Parameter containing:
tensor([[ 0.0267, 0.0427, -0.0713, ..., -0.0344, 0.0055, 0.0277],
[ 0.0228, 0.0752, -0.0429, ..., 0.0860, 0.1789, 0.0289],
[-0.0079, -0.0309, -0.0990, ..., -0.0316, 0.0335, -0.0635],
...,
[ 0.0040, -0.0065, -0.0924, ..., -0.0338, -0.0250, -0.1278],
[ 0.0134, 0.0512, 0.0694, ..., -0.0096, -0.0297, 0.0294],
[-0.0243, -0.0592, -0.0535, ..., -0.0318, -0.0714, 0.0376]],
requires_grad=True))]
print(list(module.named_buffers()))
> [('weight_mask',
tensor([
[1., 1., 1., ..., 1., 1., 1.],
[1., 0., 1., ..., 1., 1., 1.],
[0., 1., 1., ..., 0., 1., 0.],
...,
[1., 0., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 0.],
[1., 1., 1., ..., 1., 1., 1.]]))]
weight_orig텐서에weight_mask가 덧입혀져 Pruning이 적용된 새로운 weight 텐서가 모듈의 속성으로 저장되게 된다.
실험 결과를 확인해보니 random_unstructured 운동을 진행하기 앞서 원래의 무게 값이었던 weight_orig가 생긴 것을 확인할 수 있었다. 그리고 해당 운동이 적용될 지점이 적힌 weight_mask도 따로 기록되었다. 해당 기록에서 0으로 표시된 지점이 random_unstructured 운동을 통해 살이 빠지게 될 곳이다. 이제 실제로 고버트 씨의 key 부위에 운동 효과가 나타나는지를 확인해보자.
1
2
3
4
5
6
7
8
9
10
print(module.weight)
> tensor([[ 0.0267, 0.0427, -0.0713, ..., -0.0344, 0.0055, 0.0277],
[ 0.0228, 0.0000, -0.0429, ..., 0.0860, 0.1789, 0.0289],
[-0.0000, -0.0309, -0.0990, ..., -0.0000, 0.0335, -0.0000],
...,
[ 0.0040, -0.0000, -0.0924, ..., -0.0338, -0.0250, -0.1278],
[ 0.0134, 0.0512, 0.0694, ..., -0.0096, -0.0297, 0.0000],
[-0.0243, -0.0592, -0.0535, ..., -0.0318, -0.0714, 0.0376]],
grad_fn=<MulBackward0>)
놀랍게도 weight_mask에 기록된 지점에 정확히 운동 효과가 나타나기 시작했다. 그런데 해당 운동 기법에는 부작용이 있다. 고버트 씨가 원활한 활동을 하기 위해 key 부위에 꼭 남아있어야 할 지점의 살도 예외 없이 빠질 수 있다는 점이 그렇다. 따라서 대개의 경우 l1_unstructured와 같이 특정 기준 ( 해당 경우에는 L1 노름 )을 가지고 살을 빼는 운동을 진행하는 것이 바람직하다.
Pruning 중첩: 두 번째 운동, Ln Unstructured
이번에는 앞서 진행한 random_unstructured와 다른 운동을 함께 병행한다면 어떤 결과가 나올지 확인해보도록 하자. 이번에 병행될 운동 ln_structured는 Ln 노름이라는 기준을 가지고 가장 중요하지 않은 부위의 30%를 제거하기 위한 운동이다. 이때 Ln 노름의 기준이 적용되는 축은 트레이너가 입력하는 dim 값을 통해 결정된다.
1
2
3
4
5
6
7
8
9
10
11
prune.ln_structured(module, name='weight', amount=0.3, n=2, dim=1)
print(list(module.named_buffers()))
> [('weight_mask', tensor([
[1., 0., 1., ..., 0., 0., 1.],
[1., 0., 1., ..., 0., 0., 1.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[1., 0., 1., ..., 0., 0., 1.],
[1., 0., 1., ..., 0., 0., 0.],
[1., 0., 1., ..., 0., 0., 1.]])
앞서 출력한
weight_mask보다 Pruning이 적용되는 지점인 0이 더 많아진 것을 확인할 수 있다.
놀랍다. 앞서 하나의 운동을 적용했을 때보다 더 많은 지점에 운동 효과가 적용되었음을 weight_mask를 통해 확인할 수 있다. 이처럼 여러 개의 운동을 병행할 경우, 어떤 운동의 조합으로 이루어진 결과인지를 기록해둘 필요가 있다. 그리고 이는 PruningContainer라는 운동 일지에 기록되게 된다.
Permanent Pruning: 운동 체화하기
아무리 좋은 트레이너와 함께 운동한들 본인의 생활에 해당 운동 습관이 들어서지 않는 한, 건강한 몸을 지속해서 유지하는 것은 불가능하다. 그러나 의지의 고버트 씨는 트레이너로부터 받아온 운동을 모두 체득하였다. 이제 과거에 자신이 어땠는지(weight_orig), 어떤 부위에 자극이 가는 운동을 해야 하는지(weight_mask)를 참고하지 않고도 몸으로 모든 운동법을 기억할 수 있게 되었다. 즉, 이러한 지침서를 모두 없애버린 후에도 고버트씨는 영구적으로 건강한 key를 지니게 된 것이다!
P.S. prune.remove 메서드를 통해 파라미터를 영구적으로 Pruning 하지 않더라도, weight_mask를 활용해 매번 Pruning이 적용된다.
1
2
3
4
5
6
7
8
9
10
11
12
prune.remove(module, 'weight')
print(list(module.named_parameters()))
> [('weight', Parameter containing:
tensor([[ 0.0267, 0.0000, -0.0713, ..., -0.0000, 0.0000, 0.0277],
[ 0.0228, 0.0000, -0.0429, ..., 0.0000, 0.0000, 0.0289],
[-0.0000, -0.0000, -0.0990, ..., -0.0000, 0.0000, -0.0000],
...,
[ 0.0040, -0.0000, -0.0924, ..., -0.0000, -0.0000, -0.1278],
[ 0.0134, 0.0000, 0.0694, ..., -0.0000, -0.0000, 0.0000],
[-0.0243, -0.0000, -0.0535, ..., -0.0000, -0.0000, 0.0376]],
requires_grad=True))]
이제
weight_orig는 사라지고 Pruning이 적용된weight값이 다시 모듈의 파라미터로 돌아오게 되었다.
Global Pruning: 안면 전체 다이어트 (?)
key 부위의 살만 뺀다고 해서 건강해지는 것은 아니기 때문에 고버트씨는 이제 안면 전체에 적용되는 운동을 시도해보고자 한다. 이 역시 마찬가지로 진행된다. 살을 뺄 부위를 파악하고, 해당 부위들을 감량하는데 공통으로 사용할 운동 기법(pruning_method)를 정한다.
그러나 이제 고버트 씨는 특정 부위를 20% 씩 감량하는 것이 아닌 전체적으로 건강한 안면을 유지하기 위해 운동을 적용할 전체 부위의 살 중 20%를 감량하는 방법을 택하게 된다. 그리고 이처럼 전체적으로 건강해지기 위한 감량을 Global Pruning이라고 부르기로 한다.
P.S. 국소적으로 모듈 내 가중치를 퍼센티지 혹은 정수 값만큼 가지치기하는 Local Pruning과 달리, Global Pruning은 해당 Pruning 작업에 포함된 모든 레이어들 간 연결에 있어 중요하지 않은 가중치를 제거하기 때문에 Pruning에 포함된 전체 모듈들의 가중치 중 20%가 가지치기되게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
model = BertModel.from_pretrained('monologg/kobert')
parameters_to_prune = ()
for i in range(12):
parameters_to_prune += (
(model.encoder.layer[i].attention.self.key, 'weight'),
(model.encoder.layer[i].attention.self.query, 'weight'),
(model.encoder.layer[i].attention.self.value, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.2,
)
모델 내에서 가중치의 영향력을 보던 Local Pruning과 달리 Global Pruing은 가중치들 간의 영향력을 토대로 가지치기가 수행된다.
의지의 한국인 고버트 씨는 자신이 감량하고자 한 전체 Self-Attention 부위 중의 20%에 해당하는 4246733 그램… 총 4톤의 감량에 성공하였다. 비록 이번에는 안면인 Self-Attention 감량에만 성공하였지만, 그의 의지라면 embeddings, pooler 등의 다른 부위들도 감량하기에 충분할 것이다. 아니면 Pruning 말고 Quantization, KD 등 새로운 운동을 찾아 나설 수도 있고 말이다.
그의 더욱 상세한 다이어트 일지가 궁금하다면 담당 트레이너가 직접 기록한 일지를 찾아보는 게 좋을 것이다. 아마 더 자세한 정보를 알게 될 수도?